I was having a similar issue (Excel changing the date format) and did a bunch of searches to figure out what was going on.
Apparently Excel (when dealing with csv files) will adjust the date field to match a windows localization setting. This is VERY frustrating.
I then noticed that Google sheets doesn’t do this auto adjust. Conveniently, I collect my wellness data in a Google Sheet so it’s just a matter of exporting to csv format but NOT opening that file in Excel before uploading to intervals.
All works well now and I’m uploading my Wellness data to intervals with the correct date format.
My advice…either use a text editor to look at your csv data…or Google sheets.
Avoid Excel when working with/viewing your csv file.
The upload will fail if a zero value is displayed as -
that is the accounting format when zero, but the download is in general format. Best is to ensure all formats are “general” with the exception of the date column (yyyy-mm-dd), and that zeros are showing as zero.
In this example of the error, row 16 refers to the 16th row of info, and not row 16 in Excel.
It all depends a lot on your locale. If you are in a region with US format, things will go smoothly.
If you are in Central European locale, it can get very messy. You need to tell Excel that the incoming data is US format by using the Import data from text wizard. In Europe a csv is expecting semi-colons as field separators because the colon is used as a decimal separator.
Once Excel knows what format is coming in, it will be displayed correctly in Excell. But if you save it, it will be saved as a csv in your locale. And uploading that to Intervals, will not work because that looks like ‘Chinese’ to Intervals…
Here’s my code that I cajoled chatgpt to write. This pulls out two columns from the smart asthma output which I can write to my google drive from the app which then syncs to my mac. I’ve set up a cron job to upload this every day at noon.
def convert_xlsx_to_new_format(xlsx_file):
# Read the XLSX file into a DataFrame
df = pd.read_excel(xlsx_file)
# Extract only the date portion from the "Blow date" column
df['Blow date'] = pd.to_datetime(df['Blow date']).dt.date
# Create a new DataFrame with only "Blow date" and "Peakflow" columns
new_df = df[["Blow date", "Peakflow"]]
# Rename the columns to "date" and "PeakFlow"
new_df.columns = ["date", "PeakFlow"]
#print("Uploading to Intervals.")
athlete_id = "<your ID>"
api_key = "<your key>"
# URL of the API endpoint
url = f"https://intervals.icu/api/v1/athlete/{athlete_id}/wellness"
# Encode API key for Basic Authentication
credentials = base64.b64encode(f"API_KEY:{api_key}".encode("utf-8")).decode("utf-8")
headers = {"Authorization": f"Basic {credentials}"}
# Define the new entry for checking its actually working
#new_entry = pd.Series({"date": "2023-12-07", "PeakFlow": 700})
# Append the new entry to the DataFrame
#new_df = pd.concat([new_df, new_entry.to_frame().T], ignore_index=True)
# Sort DataFrame by "blow" column in descending order
new_df.sort_values(by="PeakFlow", ascending=False, inplace=True)
# Print rows with duplicate dates
#duplicate_rows = df[df.duplicated('date', keep=False)]
#print("Rows with duplicate dates:")
#print(duplicate_rows)
# Drop duplicates based on the "date" column, keeping the first entry (highest "blow" value)
new_df.drop_duplicates('date', keep='first', inplace=True)
# Print rows with duplicate dates
#duplicate_rows = df[df.duplicated('date', keep=False)]
#print("Rows with duplicate dates:")
#print(duplicate_rows)
# Make the POST request
response = requests.post(url, headers=headers, files={"file": ("output.csv", new_df.to_csv(index=False).encode("utf-8"))})
# Check the response
if response.status_code == 200:
print("Success!")
else:
print(f"Error: {response.status_code}, {response.text}")
#print("Script has finished.")
if name == “main”:
# Define the base path
base_path = “<path to the peak flow file”
# Specify the file names
xlsx_file_name = "peak flow.xlsx"
# Create the full file paths
xlsx_file_path = os.path.join(base_path, xlsx_file_name)
convert_xlsx_to_new_format(xlsx_file_path)
Thats cool! I think eliminating duplicates should be left to the caller. If Intervals.icu does it it has to make arbitrary decisions (merge, keep last, keep first?) and will hide bugs.
I have been learning Python myself. Doing a lot of machine learning at work.
Okay, I have the CSV loaded in Google Sheets. This is my last question on this subject. Where would I “put” the API connection to make it post today’s data?
Dear Lucas,
it’s been a while.
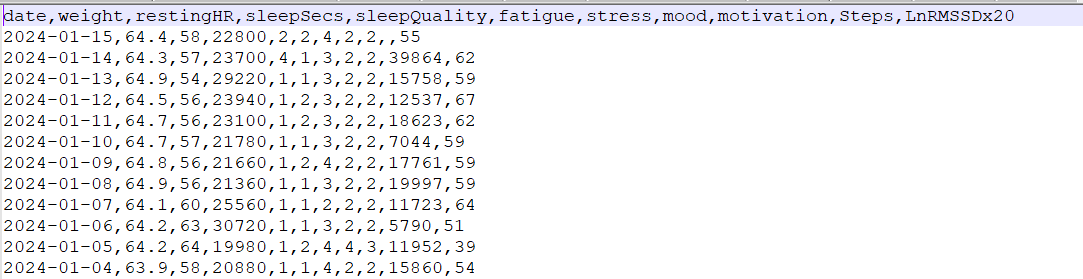
Now I have a file with more measurements, and the extracted CSV file is larger.
consider that by opening it with Numbers (I have mac), the date setting is correct as intervals wants it.
but when I load the file into Wellbeing it still tells me this.
what do you think?
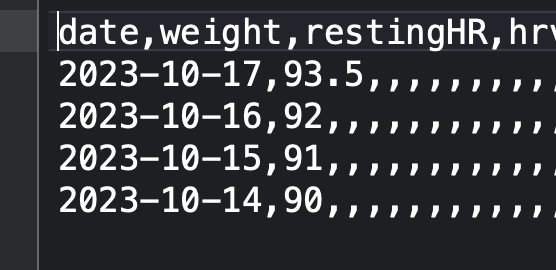
The message is clear. The FIRST column must be the date in the format expected by Intervals, yyyy-mm-dd.
Your csv file opened in a text editor must look like:
Download some Wellness data from Intervals and reconstruct that format for anything you wnat to send.
Stop using a spreadsheet or other software to open the csv files. Open them with a plain text editor.
pretty sure my manual for that was very detailed but ofc I can try to help.
just try to do it step by step (sry I barely remeber that, but I’m 100% sure there was a step to convert the data)
where can I find your file?
How did you manage to export this CSV data? from tanita smartphone app?
I managed to get API Access but it only provide data for Weight and bodyFat and not the amount of data you got from your CSV you shared prev.. sadness